
70 个人,一群 AI:矩阵起源组织重构笔记系列
第一篇:我们不能变成一人公司,所以只能把组织重写一遍
矩阵起源产品VP 邓楠
写在前面
过去这一两年,AI 对整个社会的冲击有多大,不用我多说——每个人都在自己的行业里切身感受过。
而在公司管理这个话题上,有两个词被讨论得最多。一个是我们今年年初年会的主题——"如何建设一个 AI Native 的组织";另一个,说老实话,比前者更火,叫 OPC(One Person Company,一人公司)。
OPC 的逻辑很性感:AI 把生产力释放到极致之后,一个人 + 一堆 AI 工具,就能撑起一家年营收几百万甚至上千万的公司。事实上这两年真的出现了不少这样的案例,一人公司的成功率比起十年前,确实显著提高了。你刷一下 Twitter 或者小红书,到处都是这种故事,看得人心痒。
但我们得回到自己身上,诚实地问一个问题:矩阵起源,能变成一家一人公司吗?能做成我们想做的事吗?
我们 CEO 王龙认真想过这个问题,答案很明确:不行。
做一个 toC 的 SaaS、做一个 AI 应用、做一个 newsletter,OPC 可能真的成立。但我们做的是 Data + AI 的底层基础设施——数据库内核是几十年工程积累才啃得下的活、企业级客户是一个季度一个季度跟出来的、一整套 Agent Runtime 和 Memory 的体系更不是一个人能扛的。我们这种形态的公司,装不进一个OPC 里。
所以对我们而言,"要不要变成一人公司"不是真正的问题。真正的问题是——AI 对我们这样的组织意味着什么?我们应该怎么把自己变成一个 AI Native 的组织?
这就是今年年初年会主题的由来。
说起来,我们跟 AI 打交道并不是最近才开始的——算下来已经小十年了(下一节会展开)。这么久的接触之后,我们觉得也是时候认认真真坐下来,把"AI 对组织意味着什么"这个问题讲讲清楚了。坐下来盘点矩阵起源过去几年的变化,已经很难再说"我们在用 AI"这种话了,因为 AI 早就不只是我们用"的工具,它钻进了我们的产品里、代码里、客户方案里、BD 同学的话术里,也体现在了我们的报销单里。
年会开完,我们决定把这件事认真写下来。不是对外做 PR,就是把这些年踩过的坑、吃过的红利、看明白的事和还没看明白的事,一件件摊开讲。
这个系列一共三篇:
- 第一篇(就是这篇):我们怎么一路走到"必须成为 AI Native 组织"这个节点的——行业是怎么变的,我们自己是怎么变的。
- 第二篇:我们心目中理想的 AI Native 组织,长什么样。
- 第三篇:我们已经做过的、还在做的、以及栽过跟头的那些实践。
先从第一篇开始。
一、先说说我们是谁
在聊过程之前,得先介绍一下矩阵起源这家公司,不然后面的故事少了背景。
矩阵起源(MatrixOrigin) 成立于 2021 年,官网 👉 matrixorigin.cn。我们一直在 Data + AI 这个赛道上折腾,一句话概括:做企业数据智能的底层基础设施。
但要说我们跟 AI 的缘分,得往前倒更多年。我们的创始团队,早在 2017 年就已经深度浸泡在 AI 里了——那会儿团队还在腾讯云,在腾讯云的大数据和人工智能团队,做的就是上一代的 AI 产品和项目。那是深度学习刚从学界走进工业界的年代,CV、NLP、推荐系统在各行各业铺开,团队在那几年里啃过的项目、趟过的坑,是今天我们对 AI 这件事保持长期信心的底气。所以 2022 年底 ChatGPT 一出来,我们的反应比很多公司都要快——不是因为我们先知,而是因为我们本来就在这条河里待了很久。
公司不大,含实习生一共 70 多号人,但"麻雀虽小五脏俱全":70% 是产研,剩下 30% 分布在 BD、售前、售后、市场、职能这些岗位上。正因为小,所以 AI 带来的每一点变化,我们都能看得特别清楚——每个岗位上都只有几个人,谁用了 AI、用得怎么样、产出变了多少,几乎都是"肉眼可见"。
然后也要简单讲下我们的产品,我们的产品发展得分三个阶段:

- 2021–2023 年:做一个全新的超融合的数据库。这个阶段我们的主产品只有一个——MatrixOne(matrixorign.cn/matrixone),一个云原生、超融合的 HTAP 数据库。那会儿大家对数据库的痛点很清楚:交易要一套库、分析要一套库、时序又要一套库,数据搬来搬去、一致性乱七八糟、成本还死贵。我们想做的事挺朴素:一个库把这些事都干了。这几年我们把底子打得很深,K8s、存储、计算、MVCC、事务、向量化、SIMD,一层一层堆上去。而且因为云原生存算分离的特性,我们做出了一些非常有意思的特性,我们叫 Git4Data,简单的说就是对于任意规模的数据进行完整 git 化语义的处理,包括 branch,diff,merge,cherrypick 等等,而且这种操作几乎没有任何代价。
- 2024-2025 年:从数据库往数据平台走。光有数据库是完全不够解决企业问题的,而且企业已经开始认真考虑大模型的 GenAI 了,真正的痛点其实不在数据存哪,而在数据怎么变成能用的东西——结构化的、非结构化的、视频的、文档的、日志的,一股脑堆在那儿,AI 根本吃不下。所以我们在 MatrixOne 之上做了 MatrixOne Intelligence(简称 MOI)(matrixorign.cn/moi),一个 AI 原生的多模态数据智能平台。它的定位是:帮企业把自己乱七八糟的私域数据,变成 AI-Ready 的资产。
- 2026 年:往 AI Infra 的更上层走,做 Memory 和 Agent Runtime。今年我们又往上长了一层,开了两条新产品线:一条是 Memoria——开源的 Agent 记忆层,Agent 的"大脑 RAM";一条是 Astra(matrixorigin.cn/astra)——Agent Runtime,Agent 真正跑起来的那个运行时环境。这两条线背后其实是同一件事:我们把在 MatrixOne 上做了几年的 Git4Data 能力(分支、快照、回滚、合并、diff)延伸到了 AI 层。Agent 需要"记得住事、改得了错、回得了头、跑得起来",我们数据库底座刚好能提供这一整套能力。与其让 Agent 层各自重新造一遍轮子,不如我们把这一层做成标准件。
简单说就是:数据库 → 数据平台 → Agent 的记忆与运行时。三层叠在一起,是我们现在完整的产品图谱。
这只"70 多人的麻雀"身上接下来发生的事,就是下面要讲的故事了。
二、行业是怎么变的:从聊天,到干活
在讲我们自己之前,还得先把外头的大风向说两句,不然单看内部会看不明白。
过去三年,AI 行业的主旋律其实就一句话:从"帮你生成内容"变成了"直接帮你把事做完"。
2023 年大家疯狂追捧 ChatGPT、Midjourney 的时候,AI 干的是生成——写一段文案、画一张图、写一段代码片段。你得自己把它的输出接到下一步去。到了 2025、2026 年,AI 干的是任务——"帮我把这个季度的数据拉出来做个报表发给 CEO"、"帮我把这个 bug 修了,顺便把测试也写了"、"帮我把这个客户的背调做一遍,写成备忘录"。中间所有的步骤,它自己搞定。
这就是所谓 GenAI → AI Agent 的跳跃。
这里借用 OpenAI 官方公开过的"AI 五阶段"框架来对一下坐标,会特别清楚。这是一个金字塔:

- L1 Chatbots:能自然语言聊天的 AI。你问它答,限于对话场景。2023 年的 ChatGPT 就是典型代表。
- L2 Reasoners:能在人类水平上解决问题的 AI。它不只是闲聊,而是能像一个研究生一样去做推理、做分析。这是 2024–2025 年大模型竞赛的主要战场。
- L3 Agents:能替你执行任务的系统。它不再等你问,而是自己规划、自己调工具、自己跑流程,最后把结果交到你面前。
- L4 Innovators:能辅助发明和创造的 AI。在科研、工程、艺术上产出真正原创的东西。
- L5 Organizations:能干一整个组织的活的 AI。
我们的判断是,2026 年整个行业正从 L2 大规模迈进 L3,一部分先锋场景已经摸到了 L4 的门口。换句话说,AI 正在从"回答问题的东西"变成"完成任务的东西"——而这个转变,就是为什么"组织怎么办"突然变成了一个必须回答的问题。因为当 AI 从回答者变成执行者,它就进入了原本属于人类组织的工作场景,所有旧的协作方式都要被重新审视。
这就是外部的大背景。下面回到我们自己。
三、我们自己的四年:五个阶段
矩阵起源跟 AI 打交道的这四年,我给它切了五个阶段。
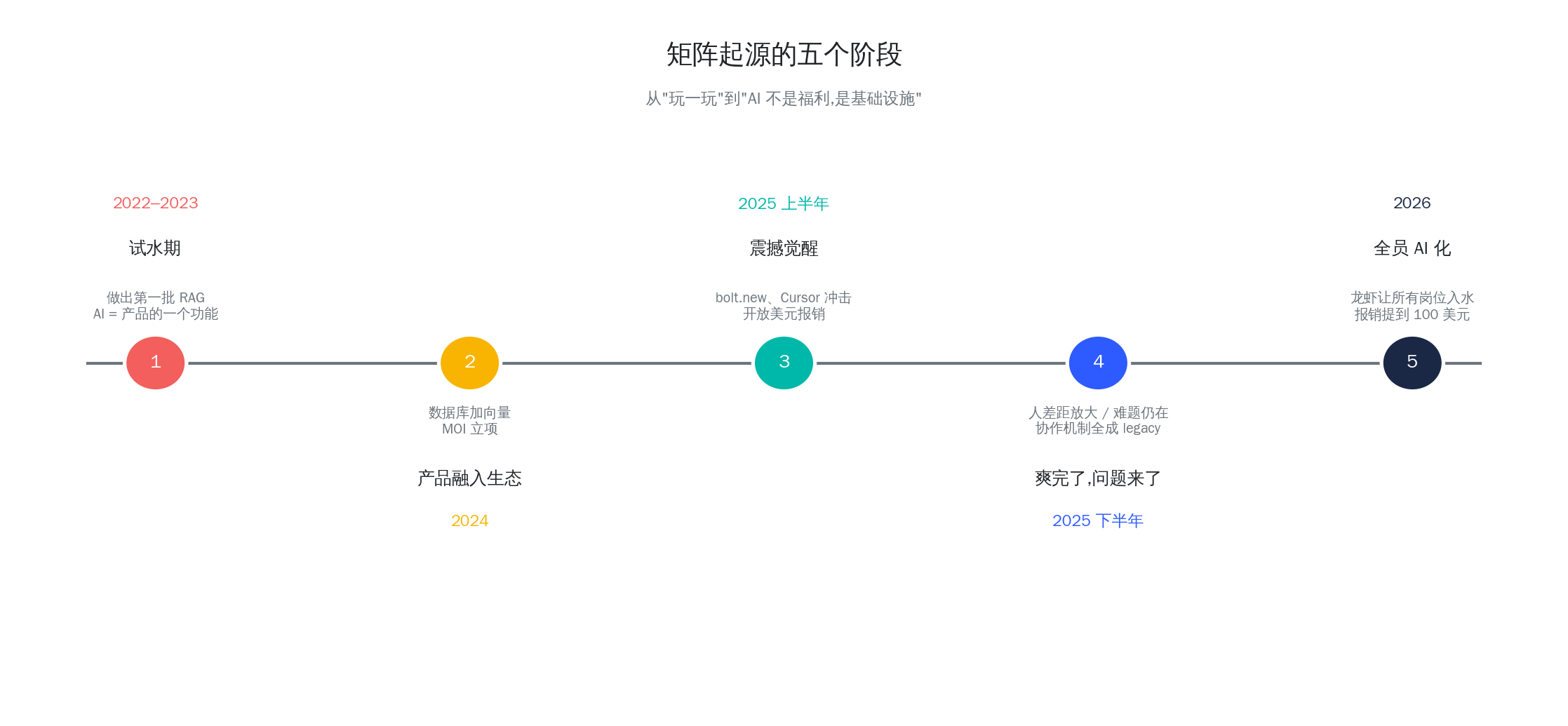
第一阶段:2022–2023 ——"嗯,这东西挺有意思"
2022 年底 ChatGPT 出来的时候,老实说,和大多数公司一样,我们第一反应是"玩一玩"。我在内部群里发了个截图,大家围观,试各种奇怪问题,一边笑一边感叹。但作为一家 Data + AI 背景的公司,我们对这类技术的嗅觉比普通公司灵敏一点,很快就从"玩"转到了"试"。
2023 年,我们做了行业里第一批 RAG 应用——给自家数据库 MatrixOne 的使用手册做了个 chatbot。想解决的问题很土:用户老是翻不到文档。我们产品文档几百页,一个参数藏在犄角旮旯,客户问技术支持的问题 80% 其实文档里都有,但没人看得动。做了 chatbot 之后,客户满意度立刻上了一个台阶。
今天回头看,那会儿的 RAG 粗得不能看:切块、向量化、检索、拼 prompt,五个步骤全是最朴素的做法。但它确实管用。
这个阶段 AI 对我们来说,就是产品的一个功能组件,仅此而已。没人会想"AI 要改变组织"这种大词,太早了。
第二阶段:2024 ——"让我们的产品融进 AI 生态"
2024 年,我们主要的动作发生在产品侧。
第一件事,我们在 MatrixOne 里加了向量检索和全文检索——让这个原本管交易和分析的数据库,也能承接 AI 应用背后的数据底座。第二件事也是更重要的一件事,我们开始立项做 MOI。
做 MOI 的出发点其实很朴素。那一年我们见了太多客户,所有人都在问同一个问题:"我们公司有几十 T 的数据,PDF、Word、图片、日志、数据库表都有,AI 到底怎么帮我们用起来?" 我们发现这个问题光靠数据库解决不了,得往上一层走,做一个面向 AI 的数据中枢。
所以 2024 年我们的心态是:产品要融进 AI 生态。AI 是这波浪潮的核心,我们争取做这个生态里最好的 Data 层。
但我必须说实话——这个时候,我们脑子里的"AI"和"组织"仍然是两件事。AI 是产品的事,组织还是组织的事,两条线没交汇。
第三阶段:2025 上半年 ——"卧槽,这不行"
真正让我们组织层面出现转变的,是 2025 年初那几个月。
开始是某个特别急的项目上,需要做个原型, 我们的研发负责人发我了个链接:bolt.new。他说:"你们都试试,我刚刚十分钟画了一个产品原型。" 大家点开链接,各自花了点时间,然后群里就安静了。因为这东西不是"提升效率"——它是重新定义了"产品原型"这件事。以前产品经理画原型要开 Figma、拖组件、配色、标注,快则几天,慢则一周;bolt.new 让这件事变成了"你描述一下,它给你做一个能跑的"。
紧接着是研发同学开始用 Cursor。Cursor 带来的冲击比 bolt.new 还大,因为代码是我们的主业。用得深的几个同学,明显开始出现"一天的工作量顶一周"的情况。我印象最深的是一位最资深的内核同学,有天在内部分享会上说了一句话:"我现在不写代码了,我在审代码。" 当时台下笑成一片,但笑完大家都沉默了——因为所有人都明白他不是在开玩笑。
意识到这股风真的来了,我们当时做了一个很关键的决定:给全员开美元报销额度,自己买自己需要的 AI 工具。
为什么不统一采购?因为 AI 工具这东西,差异太大了,不同岗位、不同习惯、不同场景,合适的工具完全不一样。与其公司花大价钱买一个席位然后没人用,不如把钱直接给到个人,让每个人自己挑。这个决定在 2025 年初是挺前卫的,当时大部分公司还在纠结"要不要买 ChatGPT Plus 的企业版"。
这半年是很快乐的半年,我们管它叫"个人生产力的春天"。但冷静下来看,这个阶段的进步仍然只发生在个体身上。AI 放大的是一个一个的人,不是组织。
第四阶段:2025 下半年 ——"爽完了,三个问题也来了"
下半年,随着模型越来越聪明、Agent 越来越能干,个人生产力又上了一个台阶。最典型的是研发侧——日常的业务代码、SDK 封装、测试补全,这些可以端到端丢给 Claude Code、Codex 这种 Agent 去做。
听起来很爽对吧?但也就是这半年,我们第一次清清楚楚看到了瓶颈。有三件事我一定要写下来,因为它们深刻改变了我们对 AI 的认知。
问题一:人和人之间的差距,被放大了十倍
同样的 AI,在不同人手里,效果能差十倍。
这不是夸张,是真实的倍数。用得好的同学,生产力是十倍百倍的放大;用得不好的同学,也就 30%–50% 的提升,有时候甚至是负的。差距在哪?不在技术,在思维方式。一个有经验、有自己思考框架、能把问题拆清楚的人,跟 AI 配合起来就像虎添翼;一个习惯了"被动执行任务"的人,让他去指挥 AI,他也不知道怎么指挥,最后 AI 给他吐一堆东西,他还得花大量时间返工。
非研发岗也是一样。资深产品经理用 AI 简直是神兵利器——画原型、写 PRD、做客户方案,全是倍增。普通产品经理用 AI,很多时候只是让 AI 机械地产出一堆看起来对的文字,然后他自己还得从头改一遍。
这件事的另一个副作用,我们也不回避——2025 下半年我们淘汰了一批同学,主要是那些思维明显固化、无论怎么辅导都跟不上 AI 节奏的人。不是业绩不好,是跟不上整个组织的加速度。这个决定做得并不容易,但拖着对谁都不公平。我们后来在内部复盘时达成了一个共识:AI 时代的组织,对"学习速度"的要求会远高于对"存量能力"的要求。
问题二:AI 很强,但真正难的问题,还是做不了
不要被那些 demo 骗了。
Agent 能端到端搞定常见的业务代码,但我们数据库内核里那些真正难的 feature——复杂的查询优化、事务的一致性边界、内核里微妙的 corner case——交给 Claude Code 和 Codex,它们还是搞不定。有个复杂的问题,交给 AI 两个礼拜都没搞定。AI 能帮你写脚手架、能帮你补测试、能帮你把样板代码堆起来,但最硬核的那 5%,还是要靠那几个最懂的人。
这件事给我们的启发是:AI 不是"什么都能干",它是在大量平均水平的工作上超过你,但在真正的专家级工作上,它还差得远。所以组织里不能因为 AI 来了就"去掉专家",恰恰相反,那几个能搞定最硬核问题的人,在 AI 时代反而更值钱了。
问题三:软件行业过去十几年建立的协作机制,全是"给人看的"
这件事是我们下半年最大的发现,也是最扎心的发现。
我们公司过去花了大量功夫建协作机制:代码仓库有规范的 PR 模板、文档中心有严格的写作规范、代码 review 有一套流转流程、甚至企业微信里的项目讨论组都有固定的同步节奏。我们一直觉得这是好事——协作越规范,效率越高。
但 2025 下半年 AI 开始真正参与生产之后,我们发现了一件可怕的事:这些协作机制,全都是设计给人看的,不是给 AI 用的。
- 以前人写代码,一天几个 PR,每个几十到几百行,reviewer 慢慢看;现在 AI 写代码,一天几十个 PR,单个上万行,原来的 review 流程完全形同虚设。
- 以前的文档是写给人读的——段落很长、图示暗含了大量背景、关键信息常常藏在"大家都懂"的语境里;现在 AI 要消费这些文档去完成任务,它读不懂那些"隐含前提",上下文一缺就开始瞎猜。
- 以前企业微信的项目群是最快的信息流转渠道——一句话一条消息、图片截图、顺手的"@ 一下"——但这些信息 AI 完全进不去,变成了组织里的信息黑洞。Agent 要跨项目工作时,最大的障碍不是算法,是它不知道上下文在哪,因为上下文全躺在企微群里,没有结构化地沉淀下来。
换句话说,过去所有为人类协作优化的产物,在 AI 时代全部变成了 legacy。代码规范、文档结构、review 流程、聊天记录——都要重新想一遍:这东西到底是给人看的,还是给 AI 看的?还是两个都要兼顾?
我们内部年底复盘的时候,反复讲一句话:"个人解放了,组织没跟上。" 这句话现在想起来还觉得刺耳。
第五阶段:2026 ——"现在是所有人的事了"
进入 2026 年,龙虾(OpenClaw) 的爆发,把生产力升级这件事推到了一个新的量级。
这一次跟以前不一样了——以前 AI 红利主要落在程序员和产品经理这种"离 AI 近"的岗位上,非产研同学多少还是旁观者。但龙虾出来之后,所有拿电脑办公的白领都被拽进深水区了。
我们公司最出圈的一个故事,主角不是程序员,而是一位资深 BD 同学。他把龙虾用出了我们内部"教科书级别"的水平:客户背调、行业资讯聚合、会前准备、会议纪要、复杂提案初稿、报价比较、竞品分析……整条 BD 工作流几乎全嵌进了龙虾里。他一个人的产出,在没扩团队的情况下翻了好几倍。我们后来开玩笑说,他一个人抵得上一个小型 BD 团队。
类似的故事在 2026 年上半年越来越多,而且越来越多地出现在非产研岗位上。市场、职能、售前、售后,每个岗位都冒出几个"AI 重度用户"。到这个时候我们终于承认一件事:公司里已经没有一个岗位可以跟 AI 脱钩了。
于是我们做了第二个组织层面的决定:把全员报销额度提高到 100 美元/月,生产力特别高的同学 Token 无上限。说白了就是:只要你用得起来、用得出东西,公司兜底。
内部传达的时候我们是这么说的:"AI 不再是福利,是基础设施。"
四、四年下来,我们看清了四件事
写到这儿,这四年的故事基本讲完了。最后我想把这四年里我们学到的、最核心的几件事,单独拎出来说一说。这是我们敢写这个系列、敢谈 AI Native 组织的基础。
第一件:AI 是一面放大镜,而不是一台印钞机。
我们一度以为,把 AI 给大家,生产力就会平均地涨一截。结果不是这样。AI 就像一面放大镜,把每个人原本的思维结构、工作方式、判断力,清清楚楚放大出来。厉害的人被放大成更厉害,平庸的人只是被加速,而不是被提升。这意味着组织不能只发工具,你得同时发"怎么用工具的能力"——培训、SOP、最佳实践沉淀、同伴之间的互相学习。这不是一件自然而然的事,必须被设计出来。
第二件:AI 不是"什么都能干",最难的问题依然要靠人。
在大量中等难度的工作上,AI 已经超过了平均水平的员工。但在真正的专家级工作上,它还差得远。所以组织的策略不是"用 AI 替代人",而是用 AI 解放人的精力,让最懂的人去啃那 5% 最难的骨头。
第三件:个人生产力不会自动变成组织生产力。
这是过去一年给我们最深的教训。个体的暴增反而暴露了组织流程、协作方式、评审机制、治理手段里所有的短板。一个写代码飞快的团队,如果 review 跟不上,最终交付的质量可能比以前更差。更深一层的问题是,过去所有为人设计的协作产物(文档、规范、聊天记录),都要在 AI 时代重新评估一遍——它们是继续用、要改造、还是要推倒重来?
第四件:新的瓶颈跟旧的瓶颈,完全不是一类问题。
旧瓶颈是"产不出来",所以大家拼命招人、拼命加班。新瓶颈是"产得太多、消化不了、质量管不住、责任说不清"。这完全是另一个物种的问题。靠多招人解决不了,靠更努力也解决不了。它要求组织形态本身发生变化。
结尾:从"用 AI 的组织"到"AI Native 的组织"
讲到这里,下一个问题已经自然浮出来了:
既然个体已经被 AI 深度重塑,而组织还停留在旧形态里,我们该把组织变成什么样?
这就是今年年初我们年会主题的由来,也是下一篇要展开的内容——我们心目中理想的 AI Native 组织到底长什么样,我们总结出了哪些原则、哪些层次、哪些必须做的取舍。
下一篇见。
*本文是「70 个人,一群 AI:矩阵起源组织重构笔记」系列的第一篇。了解我们的产品,欢迎访问 matrixorigin.cn