
矩阵起源(MatrixOrigin)专注于将先进 AI 能力深度融入企业核心业务。借助 AI 驱动的能力,企业可以自动化复杂的工作流,将运营效率提升到远超传统方式的水平,此外,沉淀于业务场景中的深度洞察,更让此前难以触达的战略决策成为可能。
安利(Amway)是全球健康与保健行业的领导品牌,安利中国是安利全球最大的市场,旗下庞大的销售团队高度依赖产品知识与客户互动能力。矩阵起源(MatrixOrigin)为安利销售代表量身打造了一款 AI Assistant,销售代表可快速检索案例、查阅资料,并基于经审核的知识库为客户推荐产品与健康解决方案,在客户沟通中实时获取洞察与建议,全面提升销售效率与服务质量。
金盘科技(JST)全球电力设备供应商,也是制造业单项冠军示范企业。矩阵起源(MatrixOrigin)为其构建了 AI 原生数据底座,将海量 ERP 与 MES 记录转化为洞察与商业智能,支撑财务、销售等业务决策。
安利与金盘科技的企业级 AI 平台,都需要同时管理结构化数据(通常以数据库表/行的形式存在)与非结构化数据(文档、图像,以及基于嵌入向量的向量索引)。MatrixOne 数据库通过将传统关系型能力与高性能向量索引相结合,实现统一的数据检索方式。为了给大语言模型(LLM)提供精确上下文,MatrixOne 可执行混合查询(hybrid query):在嵌入文档分块(chunk)上进行向量相似度搜索的同时,对元数据与事务记录施加标准 SQL 过滤条件。
AI 试点项目一旦取得初步成功,往往会在组织内快速扩散、规模化落地。然而,当数据量与查询并发按百倍规模增长时,平台会面临重大工程挑战:如何在性能不显著下降的前提下,支撑数千万级高维向量的构建和查询。
为满足这一需求,我们将 NVIDIA cuVS 与 RAFT 库深度集成到 MatrixOne 数据库引擎中。该架构已在安利与金盘科技的生产环境中部署,使用 NVIDIA H20 GPU,显著加速了向量索引构建和查询负载。通过利用 GPU,而非传统「加服务器节点」的横向扩展方式,我们可以更高效地扩展算力,同时降低硬件开销与能耗。
挑战:MatrixOne 数据库中的巨型向量索引
MatrixOne 原生支持向量数据类型(Vector Datatype)与 IVF-Flat 向量索引,但在扩展到数千万向量、且仅依赖传统 CPU 执行时,会暴露出明显的计算瓶颈。这些挑战体现在两个不同阶段:索引构建与查询执行策略。
索引构建阶段
- 聚类中心(Centroid)数量不能太少,否则检索时需要访问过多向量。
- 通过 K-Means 聚类计算大量中心点,在 CPU 上计算昂贵且缓慢。
- 中心点确定后,数千万条向量中的每一条都必须分配到最近的中心点,这一过程可能耗时数小时。
查询阶段
在真实企业 SQL 负载中,向量检索几乎从不单独发生,通常会伴随关系型元数据上的谓词(Predicate)约束。这给 MatrixOne 查询引擎带来复杂的优化问题:
- 预过滤(Pre-Filtering,先关系后向量):若引擎先执行元数据谓词,可能将数据集过滤到很小比例;但若剩余集合仍然很大,引擎必须对每条幸存向量做「暴力(Brute Force)」距离计算 —— 因为预过滤往往破坏了已构建 IVF 索引的结构效用。
- 后过滤(Post-Filtering,先向量后关系):若引擎先查向量索引得到 Top-K 近邻,后续关系谓词可能丢弃大量结果,导致召回率(recall)偏低。为弥补召回率损失,引擎被迫增大nprobe以搜索更多聚类中心点(Centroid),进一步增加算力需求。
基准测试环境
在详细说明 NVIDIA cuVS 库如何逐步集成进数据库之前,需要先定义测试环境。为评估性能与可扩展性,我们使用简化 Schema ,模拟真实企业 AI 负载。
CREATE TABLE documents (file_chunk_id INT NOT NULL,
file_attribute INT,
chunk TEXT,
embedding VECTOR(768));file_attribute列存放关系型元数据 —— 如部门 ID、安全标签、创建时间戳 —— 用于约束混合查询。
为填充高维数据,我们使用 NVIDIA 提供的 wiki_all 数据集(8800 万条 768 维嵌入向量,未压缩约 251 GB)。测试在 AWS g6e 实例上进行,搭载 NVIDIA L40S GPU(48 GB 显存),扩展策略如下:
- 100 万~1000 万向量: 在 g6e.16xlarge 实例上使用单 GPU 测试
- 8800 万向量(完整数据集): 在 g6e.48xlarge 实例上使用 8 GPU,应对完整语料库的算力与内存需求
NVIDIA cuVS / RAFT 与 MatrixOne 数据库的集成
以下是对将 NVIDIA cuVS 与 RAFT 能力嵌入 MatrixOne 数据库的技术拆解。
步骤 1:为索引构建计算聚类(中心点)
构建 IVF-Flat 索引的第一阶段是确定最优中心点。我们使用 cuVS 的 Balanced K-Means 算法,并采用sqrt(n)启发式确定中心点数量。对于 8800 万条记录,约产生10,000 个中心点。借助 GPU 加速聚类,中心点计算时间从 CPU 上的数分钟缩短到数秒。
步骤 2:将向量分配卸载到 GPU
中心点确定后,库中每条嵌入向量都必须映射到最近的中心点。为此,我们针对中心点构建了 NVIDIA cuVS Brute-Force Index索引;通过批量处理嵌入向量,将穷举距离计算卸载到 GPU,将通常耗时数小时的过程压缩到数分钟。
步骤 3:GPU 资源管理
MatrixOne 主要使用 Go 语言编写,因此需要一座桥梁连接 NVIDIA 基于 CUDA 的 RAFT 库。我们实现 C++ 工作线程管理长生命周期 GPU 资源,使每次请求的 GPU 初始化成本接近零。为降低跨语言调用(Go → C++ → CUDA)开销,对 cuVS 的请求尽可能批量处理,在高并发查询下仍保持高吞吐。
步骤 4:通过自动量化(Auto-Quantization)优化内存
管理数千万高维向量会带来显著内存压力。我们使用 NVIDIA cuVS 的量化例程实现自动类型量化;所有转换均直接在 GPU 上完成,避免占用 CPU。采用 NVIDIA cuVS IVF-PQ(Inverted File Product Quantization,倒排文件乘积量化)索引后,可大幅压缩内存占,使整个索引能够驻留在 GPU 显存中,实现极快检索。
步骤 5:混合查询的谓词下推(Predicate Pushdown)
对于「查找 Top 20 相关记录,且 file_attribute = X」这类混合查询,MatrixOne 使用谓词位图(predicate bitset) 将关系谓词直接下推到 cuVS 执行引擎。由于 file_attribute 等元数据相对较小,MatrixOne 可将其保留在内存中并快速生成位图。该位图与向量搜索(例如使用 CAGRA 或 IVF-PQ)一并传给 cuVS;cuVS 确保只返回满足元数据约束的 Top-K 结果,避免低效的后置剪枝,显著提升召回率与性能。
性能表现
为评估 GPU 加速效果,我们对比三种配置:标准 CPU 版 IVF-Flat 索引、GPU 增强索引构建(仅构建阶段卸载到 GPU),以及基于 NVIDIA cuVS IVF-PQ 的全 GPU 原生方案。
向量搜索在速度与精度之间存在权衡,我们仔细调参以维持 0.8 召回率 —— 企业客户的常用门槛。查询实验使用 100 个并发客户端连接。
索引与搜索参数在各实验中统一如下:
- 聚类配置: 所有索引的聚类数约等于 sqrt(记录数)。具体为:100 万记录用 1,000 个聚类,1000 万用 3,000,8800 万完整数据集用 10,000。
- 搜索参数: 为维持召回率,标准向量搜索使用 nprobe = 16;引入元数据谓词时,将 nprobe 提升至 32,以补偿搜索空间收窄。
- 量化: IVF-PQ 索引中 pq_bits = 8,在内存效率与距离计算精度之间取得平衡。
参数调优细节与性能曲线见附录。
索引构建时间
| 数据集 | IVF-Flat(CPU 构建) | IVF-Flat(GPU 构建) | IVF-Flat GPU vs CPU | IVF-PQ(GPU 构建) | IVF-PQ vs CPU |
|---|---|---|---|---|---|
| 100 万 | 36 s | 15 s | 2.4× | 47 s | 0.8× |
| 1000 万 | 14 min 13 s | 2 min 12 s | 6.5× | 7 min 32 s | 1.7× |
| 8800 万 | 6 h 23 min | 20 min | 19× | 50 min | ~7.7× |
基于 CPU 的索引构建仅适用于小规模数据集。扩展到 8800 万向量时,性能差距极为悬殊:CPU 构建需数小时,而 GPU 驱动的 IVF-PQ 构建约快 7~8 倍;GPU 构建的 IVF-Flat 加速可达 19 倍,将原本需要过夜的任务压缩到一杯咖啡的时间。
IVF-PQ 构建虽比 IVF-Flat 更久,但这是特意设计的:额外计算使索引在更低内存占用与更优搜索性能之间取得平衡——在检索阶段,这种「计算周期」上的 trade-off 价值充分显现。
无元数据谓词的搜索
| 数据集 | IVF-Flat(nprobe=16) | IVF-PQ(nprobe=16) | PQ vs Flat |
|---|---|---|---|
| 100 万 | 860 QPS,召回 0.86 | 904 QPS,召回 0.82 | 1.05× |
| 1000 万 | 461 QPS,召回 0.82 | 1066 QPS,召回 0.80 | 2.3× |
| 8800 万 | 4 QPS,召回 0.89 | 759 QPS,召回 0.83 | ~210× |
小规模(100 万向量)时,数据集可控,CPU 与 GPU 均可高效处理。
到 1000 万时,CPU 开始吃力,而 GPU 版 IVF-PQ 仍保持高 QPS(每秒查询数)。
到 8800 万时,差距无可争议:IVF-PQ 的架构优势成为维持搜索速度的关键——量化后整个向量索引驻留 GPU 显存,搜索完全由 GPU 服务;未量化时,原始向量数据超出数据库缓存容量,系统频繁换页,搜索性能几乎停滞。
带元数据谓词的搜索
| 数据集 | IVF-Flat(nprobe=32) | IVF-PQ(nprobe=32) | PQ vs Flat |
|---|---|---|---|
| 100 万 | 779 QPS,召回 0.82 | 649 QPS,召回 0.83 | 0.83× |
| 1000 万 | 230 QPS,召回 0.82 | 330 QPS,召回 0.80 | 1.43× |
| 8800 万 | 2.6 QPS,召回 0.82 | 80 QPS,召回 0.84 | ~30× |
关于 IVF-PQ 内存占用
8800 万条 768 维向量(float32)约 270 GB 原始数据。在此规模下,CPU 与 GPU 的差异不仅是速度,更在于数据驻留位置与内存带宽。IVF-PQ 通过激进压缩完全绕开这些内存限制:使用 M=192、pq_bits=8 等设置,索引被压缩到原始体积的一小部分,整个可搜索结构可驻留在单块现代 GPU 的高带宽 VRAM 中。此外,NVIDIA cuVS 可将 IVF-PQ 索引分布到多 GPU 集群;对完整 8800 万向量数据集,分布在 8 GPU 上时每 GPU 仅需约 3.5 GB。
结论: IVF-PQ 压缩比超过 10×。结合量化策略与 GPU 加速,单台配备最新 GPU(每卡 200 GB+ 显存)的服务器,即可无缝管理数十亿级高维嵌入向量。
结论:以 GPU 加速重新定义数据库中的向量搜索
通过 NVIDIA cuVS 将整个流水线——聚类、向量分配、量化、搜索(以及 SQL 谓词评估)——卸载到 GPU,MatrixOne 实现以前所未有的效率管理超大规模向量数据集。
关键性能突破
- 索引构建加速: GPU 索引构建相比传统 CPU 方法提速约 20×,数小时任务可在 1 小时内完成。
- VF-PQ 的赋能: 借助 cuVS,MatrixOne 可在 GPU 上完成向量的构建与搜索;量化与压缩降低内存占用,最新一代 GPU 有望承载并检索数十亿嵌入向量,满足最苛刻的客户场景。
- 架构协同: 通过将 cuVS 向量搜索与位图预过滤(bitset pre-filtering) 集成,MatrixOne 提供的不仅是快速索引,更是面向结构化数据与嵌入向量混合查询、可生产部署的数据库引擎,满足现代 AI 应用的密集需求。
附录:参数调优
在展示对比数据之前,需要先说明表中参数如何选取。对每类索引需回答两个问题:如何选择 nprobe?以及(对 IVF-PQ)量化可以多激进?我们在 1000 万 数据切片上调参——足够有代表性,又便于 sweep——目标为 Top-20 召回率 ≈ 0.80,再在 8800 万规模上验证。
我们对IVF的nprobe ∈ {1, 8, 16, 32, 64, 128, 256} 进行了帕累托扫描:
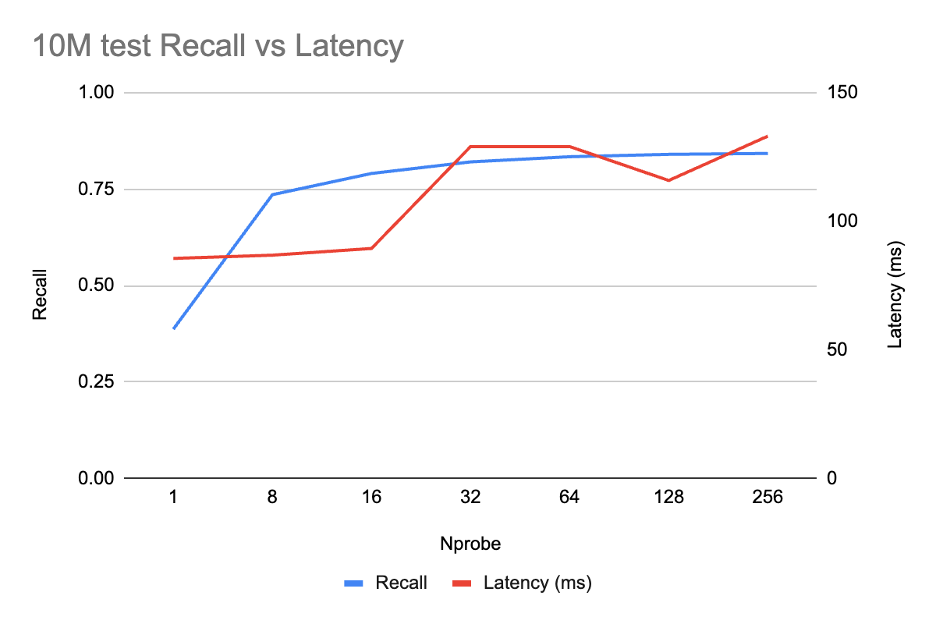
该曲线显示了经典的IVF拐点:召回率急剧上升,直到nprobe = 16(0.79),然后趋于平缓——超过这一点,nprobe每增加一倍,召回率最多增加约1个百分点,但延迟开始上升。nprobe = 16是我们0.80召回率目标的帕累托最优点。
随后我们在8800万条数据上进行了验证:
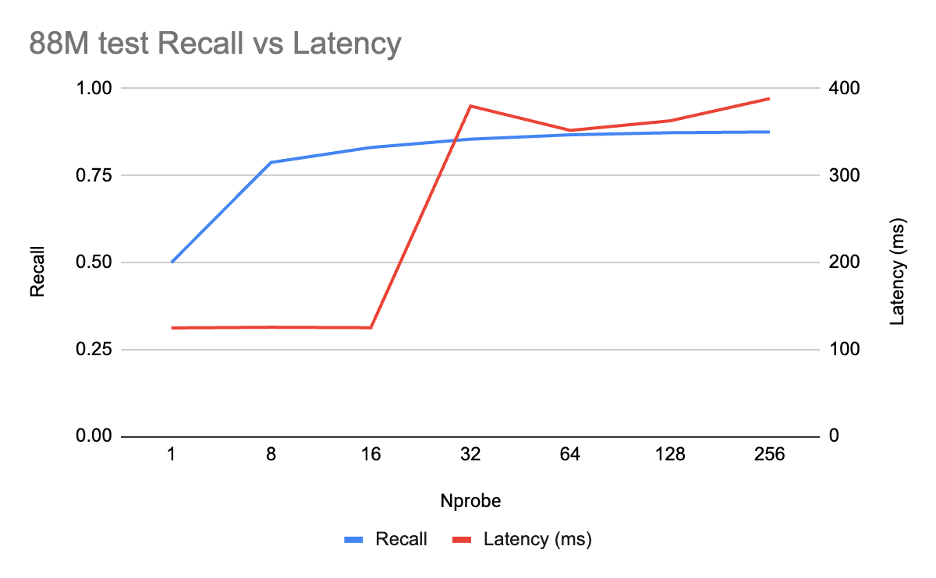
8800万条数据的曲线显示了与1000万条数据曲线相同的结果:在nprobe = 16(约125毫秒延迟)时召回率达到0.83,到nprobe = 256时仅攀升至0.88。基于1000万条数据调优的设置(pq_bits = 8, nprobe = 16)在更大规模下表现良好。
接下来,更激进的PQ压缩能否达到那个目标?我们在相同的nprobe梯度下(1000万条数据,top-20,并发数=100,n=10000)扫描了pq_bits ∈ {8, 7, 6}:
| nprobe | pq_bits=8召回 | pq_bits=7召回 | pq_bits=6召回 |
|---|---|---|---|
| 1 | 0.39 | 0.38 | 0.37 |
| 8 | 0.74 | 0.71 | 0.68 |
| 16 | 0.80 | 0.76 | 0.72 |
| 32 | 0.82 | 0.79 | 0.74 |
| 64 | 0.83 | 0.80 | 0.75 |
| 128 | 0.84 | 0.81 | 0.76 |
| 256 | 0.84 | 0.81 | 0.76 |
只有pq_bits = 8在nprobe = 16时达到了0.80的召回率。pq_bits = 7需要nprobe ≥ 64才能达到相同水平(为获得相同召回率需要4倍以上的探测次数),而pq_bits = 6在这次扫描中从未达到0.80——其渐近上限约为0.76。由于从8位降到7位只能节省约12%的存储向量字节数,我们将pq_bits设为8。
IVF-Flat没有量化旋钮——向量以float32格式不压缩存储——因此唯一可调的参数是聚类中心数量(列表数)和nprobe。我们为8800万条数据的索引设置了列表数 = 10000(≈ √N,标准启发式值)。
| nprobe | Recall@20 |
|---|---|
| 8 | 0.77 |
| 16 | 0.89 |
| 32 | 0.92 |
(8800 万 wiki_all,无过滤器,Top-20,并发 100,n=10000。)