
用 Memoria 做实际项目开发,体验怎么样?
以 store-app 项目为例,记录 Memoria 在实际开发中的使用体验、价值与局限。
背景:store-app 是什么
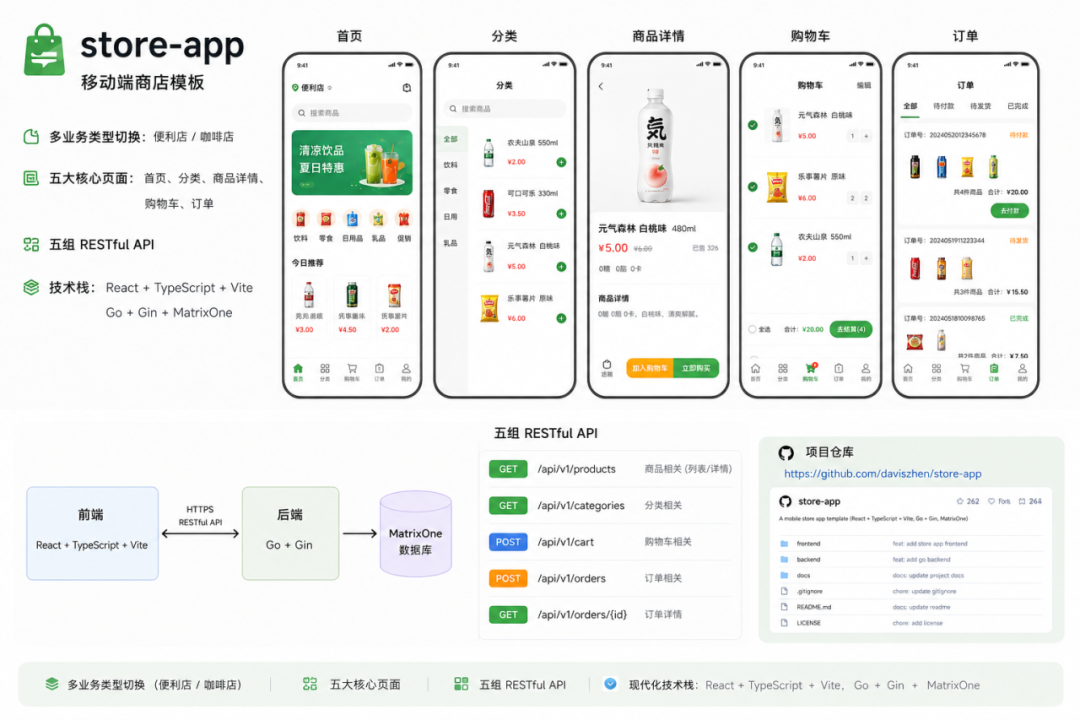
store-app 是一个移动端商店模板,前端 React + TypeScript + Vite,后端 Go + Gin,数据库 MatrixOne。支持多业务类型切换(便利店 / 咖啡店),包含首页、分类、商品详情、购物车、订单五个页面,后端五组 RESTful API。项目仓库:https://github.com/daviszhen/store-app。
Memoria 记忆 —
019e2bfd958d7c93bd5690249e09dc37项目 store-app 位于 /home/pengzhen/Documents/store-app/,是移动端商店模版。前端 React+TS+Vite,后端 Go/Gin,数据库 MatrixOne。包含首页/分类/商品详情/购物车四个页面,后端有店铺/分类/商品/购物车/订单五组 RESTful API。
项目从零开始,经历了 3 次 Git 提交:
| 提交 | 内容 | 规模 |
|---|---|---|
549f521 first | 空目录初始化 | 1 文件 |
14b8efe update | 全栈骨架搭建 | 34 文件,+4586 行 |
86bdfe7 add coffe | 业务类型切换功能 + 咖啡店种子数据 | 17 文件,+480 / -73 行 |
整个开发过程中,Memoria 作为记忆系统在后台持续记录。下面结合具体场景,分析它的实际表现。
Memoria 记录了哪些东西?
1. 项目骨架信息
开发初期,Memoria 自动捕获了项目的核心结构信息——技术栈、页面清单、API 端点、数据库表结构、启动流程。
Memoria 记忆 —
019e2bfd958d7c93bd5690249e09dc37(项目概况)项目 store-app 位于 /home/pengzhen/Documents/store-app/,是移动端商店模版。前端 React+TS+Vite,后端 Go/Gin,数据库 MatrixOne。包含首页/分类/商品详情/购物车四个页面,后端有店铺/分类/商品/购物车/订单五组 RESTful API。
Memoria 记忆 —
019e2bfdc48f7491873836727c2958a3(数据库结构)store-app 数据库表结构:store(店铺信息含主题色)、category(商品分类)、product(商品)、cart(购物车)、orders(订单)、order_item(订单明细)。
Memoria 记忆 —
019e2bfde1367673a841a6dc2459673d(API 端点)store-app 的 API 端点:GET/PUT /api/store 店铺、CRUD /api/categories 分类、CRUD /api/products 商品(支持 category_id 筛选)、CRUD /api/cart 购物车(按 user_id)、POST/GET /api/orders 订单。
Memoria 记忆 —
019e2bfdcb1d77b2aef3bfe4cec86f65(启动方式)store-app 启动方式:1) 执行 sql/init.sql 初始化 MatrixOne 数据库;2) cd server && ./server 启动后端(端口8080);3) cd frontend && npm run dev 启动前端(端口5173)。
这些信息在后来的对话中反复被引用。当我询问「store-app 的 API 端点」时,Memoria 直接返回了完整列表,不需要重新翻代码。
2. 启动故障的三个坑
这是 Memoria 记录中最有价值的一类内容。后端首次启动遇到了三个具体问题:
Memoria 记忆 —
019e2c0902497323b7562d849054bcb3(启动故障)store-app 后端启动遇到的三个问题及解决:1) 密码错误 - config.go 默认密码改为 111;2) AutoMigrate 与 init.sql 外键冲突 - 移除 AutoMigrate;3) GORM 默认复数表名 (categories) 与实际表名 (category) 不匹配 - 添加 NamingStrategy{SingularTable: true} 配置。
Memoria 记忆 —
019e2c09074e78439e32d7bda2688805(GORM 配置详情)store-app 的 GORM 数据库连接配置在 server/internal/database/database.go,使用 schema.NamingStrategy{SingularTable: true} 匹配 init.sql 中单数表名。DSN 格式:user:password@tcp(host:port)/dbname?charset=utf8mb4&parseTime=True&loc=Local。
每个问题都记录了根因和解决方案。假如隔两周再遇到同样的错误,看一眼记忆就能定位,不用重新排查。
补充:在后续开发中,又遇到了一个相关 bug——init.sql 中订单表叫 orders(复数),但 GORM 开了 SingularTable 后映射到单数 order(MySQL 保留字),需要用反引号包裹。
Memoria 记忆 —
019e315014af7d82b9cc20893105f3df(订单表名 bug)修复预存 bug:init.sql 订单表名为 orders(复数),但 GORM 使用 NamingStrategy{SingularTable: true},映射 model.Order → 表名 order。改为
order反引号包裹(MySQL 保留字)。此 bug 导致创建订单时报 Error 1146 table not found。
3. 端口漂移的轨迹
端口问题经历了三次变化,Memoria 忠实地记录了每一次:
- 初始:8080
- 8080 被占用 → 改 8090
- 后来改回 8080,并将端口从硬编码改为
.env配置
Memoria 记忆 —
019e2c06527478619e2bafb8d81accf9(端口改为 8090)store-app 后端运行端口改为 8090(8080 被占用),环境变量 SERVER_PORT=8090 启动。前端 API 地址已同步更新为 http://localhost:8090/api。
Memoria 记忆 —
019e2c0909f57281b60cffa6f6dcdb84(前端 API 配置)store-app 前端 api/client.ts 中 BASE_URL 是 http://localhost:8090/api,使用泛型 request<T> 封装 fetch,返回 json.data as T。
Memoria 记忆 —
019e3429b5e17813b656338c6e9b0bd9(端口改为配置驱动)store-app 前后端端口配置方式:后端 SERVER_PORT 环境变量(config.go 中 getEnv 读取,默认 8080)。前端 API 地址通过 .env 中 VITE_API_BASE_URL 配置,client.ts 中 import.meta.env.VITE_API_BASE_URL 读取,默认 http://localhost:8080/api。不再硬编码端口。
当我在一次对话中看到前端报 Failed to fetch 时,Memoria 中的端口记录直接帮我定位了问题:前端 client.ts 的 BASE_URL 指向 8090,但后端实际跑在 8080。
4. 业务类型切换的设计(add coffe 提交的核心)
这是项目中最复杂的一次改动。Memoria 记录了完整的设计思路:
Memoria 记忆 —
019e315011387c30850f613b41f6a6ef(咖啡店开发完成)咖啡店开发完成:store-app 支持业务类型切换。方案C — 前后端配置文件控制。后端 BUSINESS_TYPE 环境变量(coffee/grocery),前端 VITE_BUSINESS_TYPE。业务类型配置在 server/internal/config/business/ 目录,通过接口+注册表模式实现,新增业务类型只需创建 Loader 实现并 init() 注册。种子数据幂等设计(检查 store 表行数)。咖啡店数据:慢时光咖啡(#6F4E37),4分类20商品。
Memoria 记忆 —
019e315018a5720282cc747ba46f951f(咖啡店种子数据)咖啡店种子数据:商店"慢时光咖啡"主题色 #6F4E37。4 分类:☕咖啡系列(美式/拿铁/卡布奇诺/摩卡/澳白/浓缩)、🍵茶饮系列(抹茶拿铁/伯爵红茶/茉莉花茶/柠檬茶/热巧克力)、🍰甜品轻食(提拉米苏/芝士蛋糕/牛角包/火腿三明治/马卡龙)、🫘咖啡豆&周边(拼配豆/单品豆/随行杯/手冲壶)。共 20 商品,价格 15-128 元。
Memoria 记忆 —
019e31501b9c7d9097eee58f333a796a(新增业务类型步骤)新增业务类型步骤:1) 在 server/internal/config/business/ 创建新 loader,实现 Name() 和 Seed();2) init() 中 Register;3) 前端 .env 设 VITE_BUSINESS_TYPE=新类型;4) 后端 BUSINESS_TYPE=新类型 启动。种子数据幂等,无需手动清库。
5. 购物车 UI 的迭代
三次 UI 迭代,Memoria 中的记忆也随之更新:
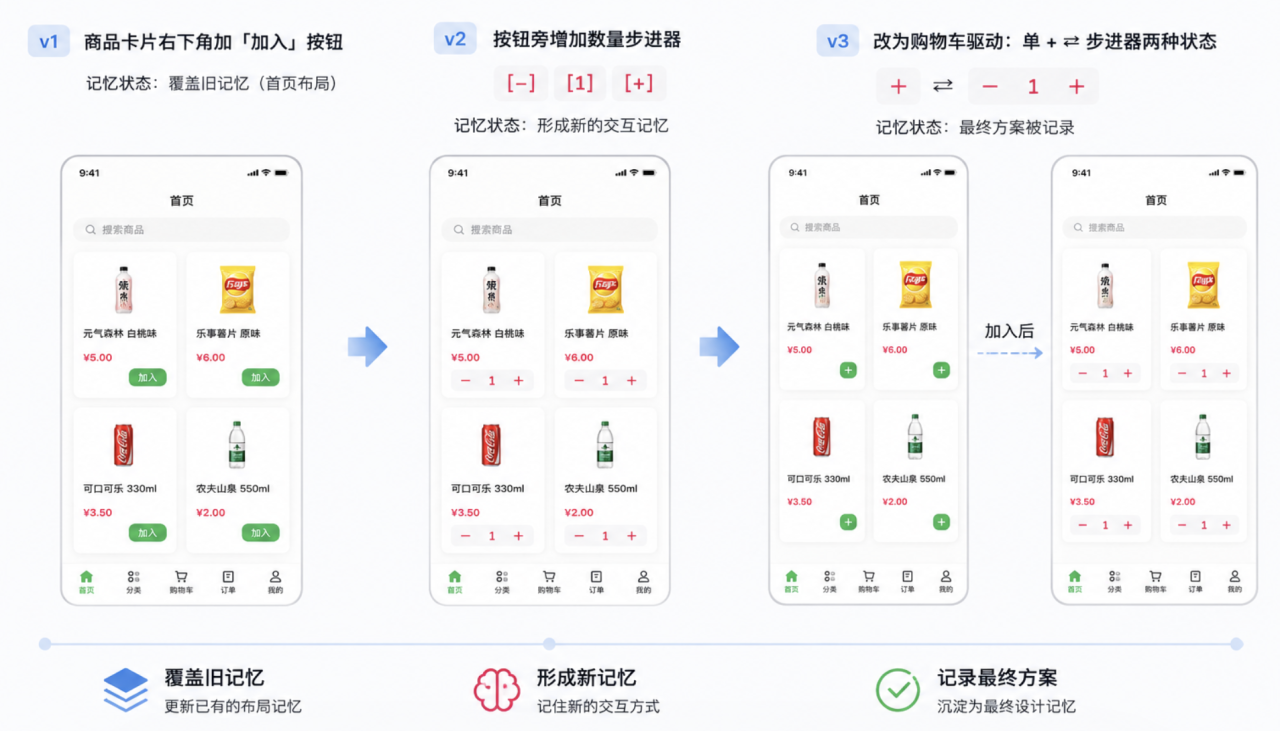
| 迭代 | 改动 | 记忆状态 |
|---|---|---|
| v1 | 商品卡片右下角加「加入」按钮 | 覆盖旧记忆(首页布局) |
| v2 | 按钮旁增加数量步进器 [-][1][+] | 形成新的交互记忆 |
| v3 | 改为购物车驱动:单 + ⇄ 步进器两种状态 | 最终方案被记录 |
Memoria 记忆 —
019e34299c5e7d90aedf2034f6164828(首页购物车交互——最终版)store-app 前端首页购物车交互:每个商品卡片右下角默认显示圆形主题色"+"按钮。点击后调用 CartContext.addItem,购物车有该商品后 UI 自动切换为步进器 [−][数量][+]。步进器"−"到 0 时调 removeItem 删除购物车项,UI 恢复为单"+"。购物车数量来自 CartContext(useCart),NavBar 角标自动同步。Home.tsx 不直接调 API,全部走 CartContext 的 addItem/updateQuantity/removeItem 方法。
6. 首页布局的演进
首页经历过从简单列表到小程序风格分类侧边栏的转变:
Memoria 记忆 —
019e2c1064fe7f43afb48e532a314780(首页布局)store-app 首页布局改为小程序风格:左侧 90px 分类侧边栏(图标+名称,高亮选中态),右侧按分类分组的商品列表,点击左侧分类自动滚动到对应区域。滚动时自动更新选中分类。
Memoria 记忆 —
019e2c1084bf7930b8dff38c796c25f6(导航栏返回按钮)store-app 导航栏在非首页时显示 ← 返回按钮(调用 navigate(-1)),首页隐藏。使用 react-router 的 useLocation 判断当前路径。
Memoria 好在哪
✅ 上下文保持:跨对话不丢信息
最实用的场景是跨对话的上下文保持。store-app 的开发跨越了多天、多次对话,每次重新开始时,Memoria 自动提供项目背景信息,不需要我重复描述。
具体例子:「list my memoria memories」,立刻拿到了 12 条相关的记忆,包括项目结构、端口配置、API 端点等。然后直接开始改代码,不需要任何热身。
✅ 跨设备恢复:停电也不怕
一个意外的场景验证了 Memoria 的「容灾」价值。周五晚上(5月15日)办公室停电,无法连接到办公室的主机。家里主机上没有 store-app 的代码,也没有打开的 IDE 上下文。
但因为 Memoria 的记忆是服务端持久化的,在家里主机上打开一个新的对话,执行 memory_list 就能立即看到所有 store-app 相关的记忆——项目结构、配置方式、最近做过的改动、甚至咖啡店的种子数据细节。不需要 VPN 回办公室找代码,也不需要凭记忆回忆「上次改到哪了」。
这相当于在代码之外,多了一份「开发的思考过程」备份。Git 仓库可以通过远程托管实现跨设备访问,但「为什么这样设计」「上次遇到什么问题」「端口是多少」这类上下文是 Git 不记录的——而 Memoria 做到了。
✅ 故障记录:精确、可检索
「后端启动的三个坑」是 Memoria 最理想的使用场景。这类信息的特点是:
- 排查时费力(三个问题互相掩盖)
- 重现频率低(可能几周后才遇到)
- 写文档太轻(不值得专门记 wiki)
Memoria 自动捕获这些故障信息,格式简洁、可检索。一个月后再接手这个项目,一条搜索就能回忆起来。
✅ 种子数据:结构化数据也有用
咖啡店的种子数据(20 个商品、价格、描述)也被记了下来。虽然不是代码级别的精准度,但在讨论阶段可以快速获取「这个业务类型有哪些商品、价格范围是多少」,不需要去翻 coffee.go 源码。
✅ 分支隔离:咖啡分支的实验
Memoria 的 branch 功能允许在不污染 main 的情况下试验。coffe 分支被创建用于记录咖啡店相关的实验性记忆。虽然当前该分支为空(记忆都合入了 main),但这种隔离机制在理论上是合理的——类似于 Git 分支对代码的隔离。
Memoria 的限制在哪
❌ 被动记录,需要手动维护
Memoria 不是「自动记一切」。大部分记忆需要我通过 memory_store 工具主动保存。如果我忘了存,关键的信息就会丢失。
具体例子:修复了「NavBar 购物车角标不同步」的问题(Home.tsx 没走 CartContext 而是直接调 API),这个 bug 的根因和修复方式值得记下来。但我确实必须手动调用 memory_store。
❌ 旧记忆不会自动更新
项目在迭代,但旧记忆不会自动同步。例如:
- 记忆
019e2c06527478619e2bafb8d81accf9说「端口 8090」,但实际已改为 8080 +.env配置 - 记忆
019e2c0909f57281b60cffa6f6dcdb84说「BASE_URL 是 http://localhost:8090/api」,但已是历史
虽然有 memory_correct 可以修正,但「发现过时 → 修正」这个循环需要人去驱动。在一个快速迭代的项目中,旧记忆积累得很快,容易产生「记忆噪音」。
❌ 没有代码级精确度
Memoria 记录的是语义摘要,不是代码。比如「修复 GORM bug」只记录了根因和解决方案,但没有记录具体的代码片段(NamingStrategy{SingularTable: true} 这个配置的确切写法和位置)。如果代码丢失了,仅靠记忆无法完全恢复。
❌ 跨分支的记忆迁移不直观
创建 coffe 分支时,我在 main 上先做了咖啡店开发,然后才创建分支。此时 main 上已经有了咖啡店的记忆,而 coffe 分支是空的。如果需要把记忆迁移到新分支,并没有一键迁移的工具。
❌ 仍然是「我一个人的记忆」
Memoria 目前是私有的,团队协作中无法共享。如果另一个开发者接手 store-app,他看不到我的记忆。和 Git commit message 不同,Git 是团队可共享的,Memoria 的记忆目前不是。
可以做得更好的地方
基于实际使用体验,提出一些可以提升的方向。
🔮 批量导出记忆,支持分享
目前的记忆是私有的、单机的。如果能将某个项目相关的记忆批量导出,就可以:
- 团队交接:新的开发者接手 store-app 时,导入一份记忆包,立刻获得项目背景、已知陷阱、设计决策等上下文
- 离线归档:项目完结后将记忆导出为文档,作为项目知识库的一部分
导出的格式可以是 Markdown(便于阅读和版本管理)、JSON(便于程序化处理)、或在 Agent 对话中以列表形式展示。本质上,这就是把 Memoria 从一个「私人备忘工具」升级为「知识库」。
🏷️ 记忆的 type 和 tier:目前只用于过滤,可以更丰富
Memoria 的记忆有两个重要的元数据字段:
| 字段 | 当前值(store-app 中出现的) | 当前用途 |
|---|---|---|
type | semantic(大部分)、procedural(2 条) | 仅用于 memory_list 的过滤条件 |
tier | T1(本文中保存的)、T3(早期自动保存的) | 仅影响 governance 清理策略 |
当前的问题:这两个字段的潜力远未被利用。
例如 type 可以扩展为一个更细粒度的分类体系:
| 建议的类型 | 适合记录的内容 |
|---|---|
semantic | 设计决策、架构权衡 |
procedural | 启动步骤、操作流程 |
bug_fix | 故障排查与修复记录 |
seed_data | 种子数据、配置清单 |
ui_spec | UI 交互规范 |
config_note | 配置说明、环境变量 |
用户在 Agent 端保存记忆时,如果能选择记忆类型(而不是全部默认 semantic),就可以在检索时精准过滤。例如:「只显示 bug_fix 类型的记忆」,就只看到启动故障、订单表名等问题记录。
tier 也是如此。当前 T1 表示「用户明确确认的事实」,T3 表示「AI 推断的摘要」。如果用户在保存记忆时能主动标记可信度——例如修正一条旧记忆时明确提升它的 tier——那么 governance 清理时就能更精准地保留高价值信息,淘汰推测性内容。
用户侧可以做的动作:
- 保存记忆时指定 type(
memory_store工具支持memory_type参数) - 对重要记忆手动提升 tier 到 T1
- 定期用
memory_correct修正过时记忆,避免 T1 信息变成噪音
💡 从被动到主动:IDE 式的记忆联想提示
这是目前 Memoria 与「理想形态」之间最大的差距。
当前的交互模式:用户主动memory_store保存记忆。主动调用 memory_list 或 memory_search 来检索记忆。记忆在后台静默存在,不会主动跳出来。这是一种 「用户拉取」模式。
期望的交互模式:类似 IDE 的代码补全。当用户在 Agent 中输入几句描述时,Memoria 在后台自动检索相关记忆,在用户输入框旁主动弹出提示:
用户输入:「store-app 的后端端口现在是多少?」
Memoria 主动提示:
🔍 相关记忆(3条):
· 端口改为配置驱动:SERVER_PORT env 默认 8080(T1)
· 端口曾改为 8090(已过时)(T3)
· 前端 VITE_API_BASE_URL 配置(T1)这种体验类似于:
- VS Code 的 IntelliSense:敲几个字符,下拉框弹出补全建议
- Google 的搜索建议:输入时实时联想相关内容
- Notion 的反向链接:打开页面时自动提示「哪些页面引用了这里」
在实际开发中,常常忘记某条记忆已经存在,于是重复描述、重复排查。如果 Memoria 能在我输入时主动提醒「你上周已经解决过这个 GORM 表名问题了,当时的原因是……」,这种「刚好在需要时出现」的体验,会让 Memoria 从「偶尔查一下的备忘本」变成「不可或缺的开发伙伴」。
Memoria 不能只是一个被动的存储箱,它应该像 IDE 的代码提示一样,在用户最需要的时候,主动地给出最相关的上下文。
🧬 记忆增加代码维度:关联 diff、commit、branch
当前的记忆是「纯文本」的——它记录的是语义描述,与代码之间没有结构化的关联。这是它和 Git 最本质的分裂点。
实际场景:有一条记忆记录了「咖啡店种子数据:慢时光咖啡,#6F4E37,4 分类 20 商品」。但想看看具体是哪个文件、哪几行代码实现了它,只能去翻 Git log。如果记忆能直接关联到:
- Git diff:这条记忆对应的代码变更(
coffee.go中Seed()方法的具体内容) - commit ID:
86bdfe7 add coffe——点一下就能跳到 GitHub 的 commit 页面 - branch:属于哪个功能分支(
add-coffe) - 具体文件与行号:
server/internal/config/business/coffee.go:15-65
那么记忆就从一个「语言描述」变成了「代码入口」。
更深层的价值:后续 Agent 在检索记忆时,不只是返回一段文字,而是可以用代码 diff 来补充和验证记忆。比如我问「咖啡店是怎么加到 store-app 里的?」,Agent 不只回答语义摘要,还能同时展示关键 diff:
+// server/internal/config/business/coffee.go
+type CoffeeLoader struct{}
+
+func (l *CoffeeLoader) Name() string {
+ return "coffee"
+}
+
+func (l *CoffeeLoader) Seed(db *gorm.DB) error {
+ // 4 categories, 20 products
+ store := model.Store{Name: "慢时光咖啡", ThemeColor: "#6F4E37"}
+ ...
+}对现有流程的改进:这需要 memory_store 保存记忆时,支持附加结构化元数据,例如:
memory_store
content: "咖啡店种子数据..."
code_refs:
- type: diff
value: 86bdfe7..HEAD -- server/internal/config/business/coffee.go
- type: commit
value: 86bdfe7
- type: branch
value: main这样一来,记忆和代码不再是两套独立的系统,而是互相指向、互相佐证。Git 回答「改了什么」,记忆回答「为什么」,而代码引用把两者缝合在了一起。
记忆 vs Git:互补而非替代
实际开发中,Memoria 和 Git 记录的是不同层次的信息:
| 维度 | Git | Memoria |
|---|---|---|
| 记录粒度 | 代码行级别的 diff | 语义级别的摘要 |
| 结构 | 有向无环图(DAG) | 扁平列表 + 分支 |
| 检索方式 | 文件名 / commit message | 语义搜索 |
| 自动记录 | ✅(commit 主动) | 半自动(需手动 store) |
| 跨设备 | ✅(远程仓库) | ✅(服务端持久化) |
| 适合记录 | 「改了什么代码」 | 「为什么这样改」「遇到过什么问题」 |
Memoria 的优势在于记录 Git commit message 写不下的东西:问题的排查过程、多种方案的权衡、失败尝试的记录。
举例:Git commit 86bdfe7 的 message 只有「add coffe」两个词。而 Memoria 中关于这个提交的记忆包含了:
Memoria 记忆 —
019e315011387c30850f613b41f6a6ef方案C — 前后端配置文件控制。后端 BUSINESS_TYPE 环境变量(coffee/grocery),前端 VITE_BUSINESS_TYPE。业务类型配置在 server/internal/config/business/ 目录,通过接口+注册表模式实现……种子数据幂等设计(检查 store 表行数)。咖啡店数据:慢时光咖啡(#6F4E37),4分类20商品。
这些信息在 Git log 中完全不存在。
总结
Memoria 在实际项目中的定位:一个「开发者的私人备忘系统」。
适合的场景:
- 跨对话保持上下文
- 跨设备恢复开发状态(停电/换机器)
- 记录排查过的问题和解决方案
- 记录设计决策和权衡
- 记录种子数据等结构化信息
不适合的场景:
- 替代 Git(不记录代码 diff)
- 替代文档(粒度太细,缺乏结构性)
- 团队协作(当前为私有)
- 自动化 CI/CD(无集成能力)
整体体验:在 store-app 的 3 次提交、多次对话中,Memoria 确实减少了重复描述项目背景的时间,并在故障排查中提供了快速定位的线索。跨设备恢复能力是一个意料之外的亮点。
但它仍处于「被动工具」阶段——需要使用者有意识地维护记忆,记忆不会主动提醒你它的存在。未来的方向是清晰的:批量导出分享能力让记忆从私人备忘变成可传递的知识,type/tier 的丰富化让检索更精准,IDE 式主动联想让记忆在需要时恰好出现,代码维度关联让记忆与 diff、commit、branch 缝合——用代码佐证记忆,用记忆导航代码。到那时,Memoria 就不只是一个「备忘本」,而是真正的「开发伴侣」。
把它当作「增强版的 Git commit message + issue tracker」,定位就准确了。但它可以走得更远。
本文基于 store-app 项目的实际开发过程撰写。项目仓库:https://github.com/daviszhen/store-app,Memoria 记忆见 main,coffe 分支。

